
Quality Gate
Date:
Beyond Checklists: A Quality Gate Based on Trust, Not Process
What this is
This is a decision framework built around one simple question:
Can I trust this build?
Not “did all the steps run”, but “do I actually believe this is safe to release?”
And just as importantly, if that belief turns out to be wrong, whether we will notice it early and be able to respond.
This framework exists to support judgment, not to replace it.
Why I created this
Most quality gates I have worked with focus on process compliance.
Tests passed. Coverage is above a threshold. Pipelines are green. QA signed off.
And yet, bugs still reached production.
In my experience, those failures rarely happened because people skipped steps. They happened because no one stopped to ask whether the steps we followed actually reduced the risks that mattered this time. We executed well, but we didn’t always think critically about what we were trusting and why.
The gap wasn’t execution. It was judgment.
I needed a way to reason about release confidence that didn’t collapse into a checklist.
What this framework focuses on
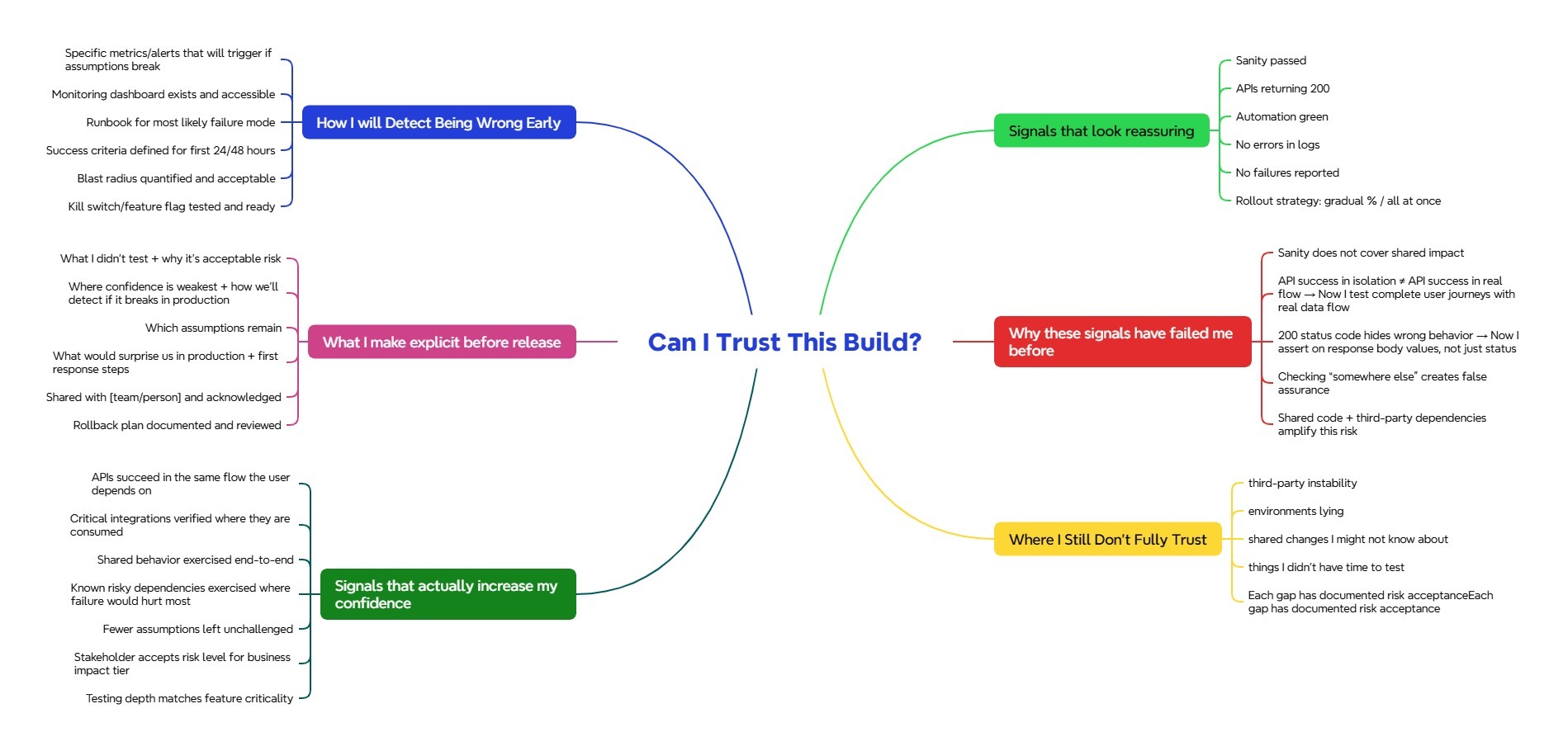
Instead of activities, it focuses on six dimensions of confidence that I have learned to pay attention to over time.
Communication
What I explicitly say before release, especially the uncomfortable parts. What I didn’t test, what assumptions remain, and where confidence is weakest.
Validation
Signals that genuinely increased my confidence, not just signals that looked good on a dashboard.
Skepticism
Green indicators I no longer trust blindly because they have misled me in the past.
Learning
Failures that changed how I test today. Incidents that taught me where my thinking was wrong.
Honesty
Areas I still don’t fully trust, documented and consciously accepted rather than ignored.
Detection
How I will detect being wrong early. What we’re monitoring, how limited the blast radius is, and how quickly we can respond.
These dimensions don’t tell you what to do.
They force you to think about why you’re confident.
The problems this framework tries to solve
One common problem is gaming the gate. Teams hit coverage numbers by testing easy code while critical paths remain lightly exercised. It’s hard to game a question like “where do we still not fully trust this system?”
Another is false confidence. All APIs return 200, but no one verified the complete user journey. Over time, I learned the difference between “this looks healthy” and “this actually makes me confident”.
There is also the one-size-fits-all problem. A cosmetic change and a payment flow rewrite shouldn’t go through the same depth of testing, yet traditional gates often treat them equally. This framework forces the question: does the testing depth match the feature’s impact?
Then there is organizational amnesia. A shared dependency breaks production, everyone scrambles, and a few months later the gate looks exactly the same as before. By explicitly capturing past failures, this framework forces learning to carry forward.
Finally, there is pressure. When deadlines loom, gates get waived. This framework doesn’t prevent that, but it requires clarity. If we are shipping with gaps, those gaps are written down and consciously accepted, not silently ignored.
Where this helps in practice
Before release
It pushes teams to talk honestly about what wasn’t tested and why that’s acceptable right now.
During release
It gives decision-makers better inputs than “everything passed”. They can see where confidence is strong and where it’s fragile.
After release
Detection and containment are part of confidence. Monitoring, alerts, rollback plans, and success criteria for the first 24–48 hours aren’t afterthoughts.
Over time
The framework evolves. Every incident feeds back into how confidence is evaluated next time.
How this differs from traditional quality gates
| Traditional gates | This framework |
|---|---|
| Did we follow the process? | Are we confident given the stakes? |
| Same rigor for all changes | Testing depth matches criticality |
| Often hides uncertainty | Surfaces uncertainty explicitly |
| Largely static | Evolves with experience |
| Measures activity | Examines risk coverage |
| “All tests passed” | “Known risky areas were exercised where failure would hurt” |
| Assumes success | Plans for failure and detection |
The difference is subtle but important.
Traditional gates focus on completion.
This framework focuses on whether completion actually reduced risk.
Who this approach fits (and where it may not)
This works best for teams that:
- own what they build in production
- ship frequently with varying levels of risk
- are comfortable exercising judgment
- value learning from incidents
It may not fit well in environments that:
- require strict regulatory audit trails
- depend on prescriptive rules due to skill variability or organizational constraints
- cannot tolerate ambiguity in decision-making
That’s not a criticism, just a reality.
The mindset shift
Traditional gates often assume consistency comes from enforcing process.
This framework assumes people are professionals who need a structure for thinking clearly under pressure.
It doesn’t remove accountability. It makes reasoning visible so others can question it, challenge it, and improve it.
The question shifts from:
Did we do everything on the list?
To:
Given what we know, what we don’t know, what could go wrong, and how quickly we can respond, should we ship?
That is the question I actually want answered before a release.